Hidden Gems: 4D Radar Scene Flow Learning Using
Cross-Modal Supervision




Presentation Video
Demo Video
Pipeline
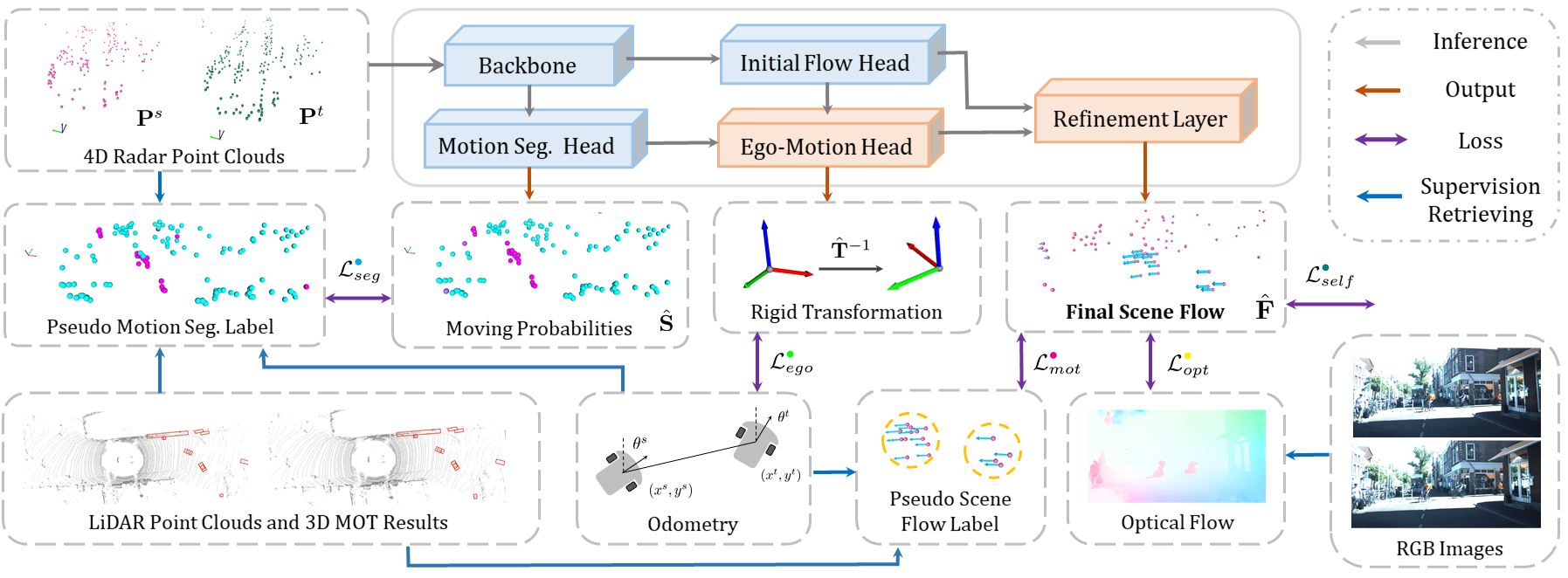
Abstract
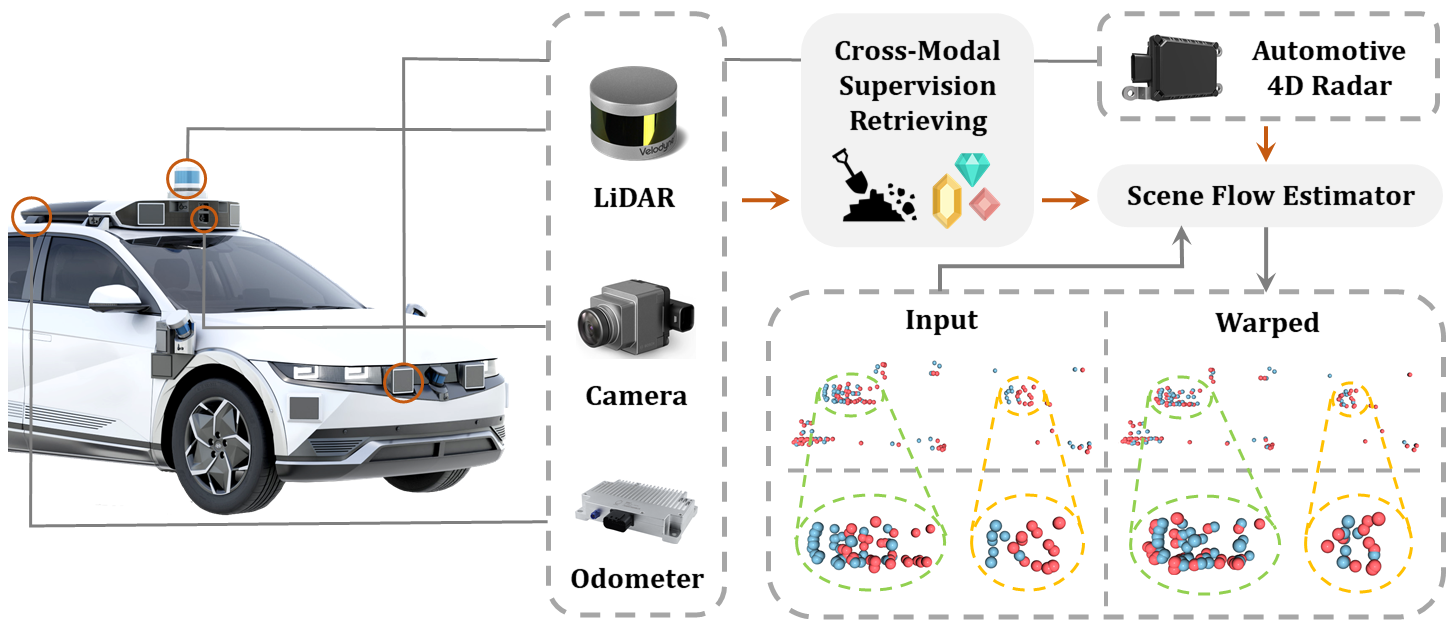
Figure 2. Cross-modal supervision cues are retrieved from co-located odometer, LiDAR and camera sensors to benefit 4D radar scene flow learning. The source point cloud (red) is warped with our estimated scene flow and gets closer to the target one (blue).
Qualitative results
Scene Flow Estimation
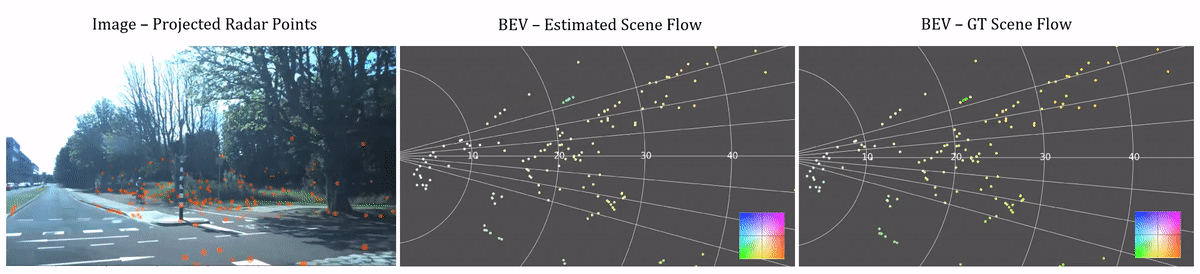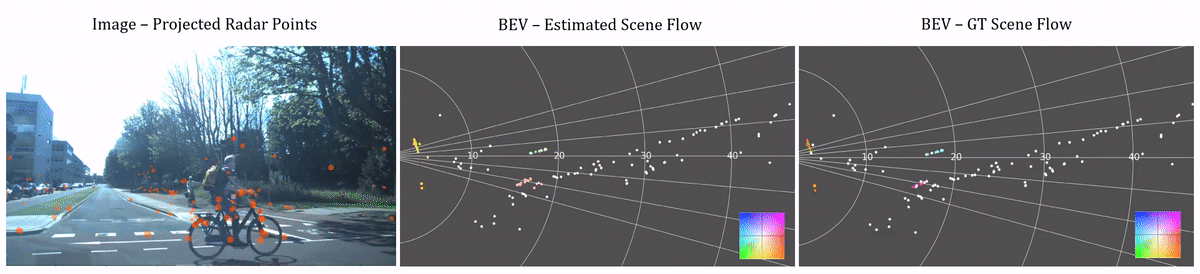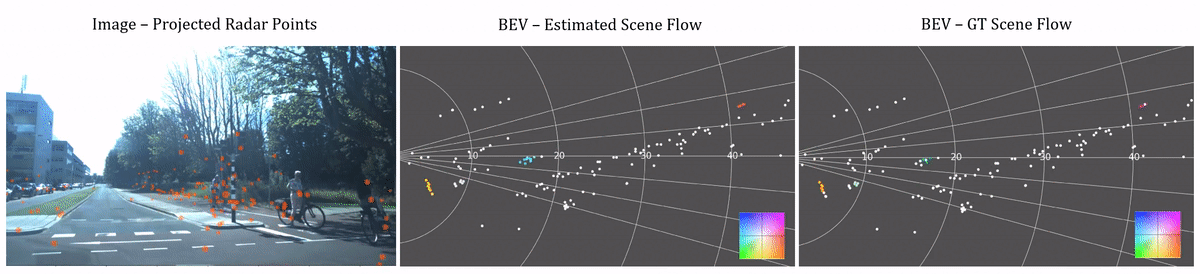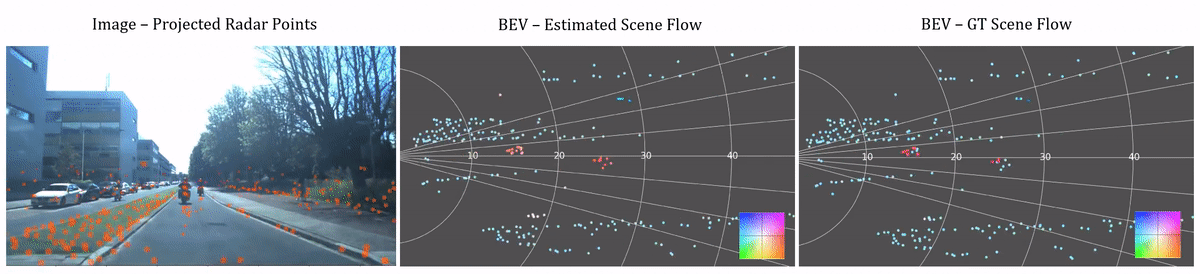

Scene flow estimation visualization. The left videos are the corresponding images captured by the camera with radar points projected to them. The middle and right columns shows our estimated and ground truth scene flow in the Bird's Eye View (BEV). Color of points in the BEV images represents the magnitude and direction of scene flow vectors. See the color wheel legend in the bottom right.
Motion Segmentation


Visualization of motion segmentation results. The left column shows radar points from the source frame projected to the corresponding RGB image. Another two columns shows our and groud truth motion segmentation results on the BEV, where moving and stationary points are rendered as orange and blue, respectively.
Ego-motion Estimation
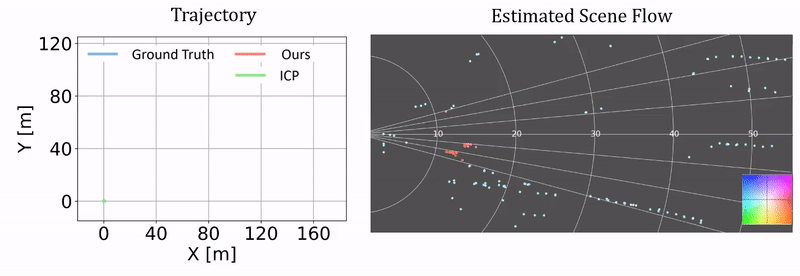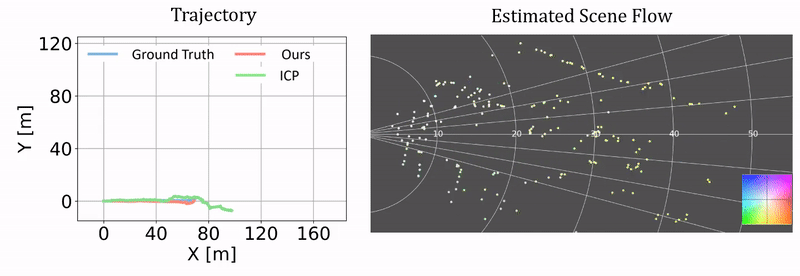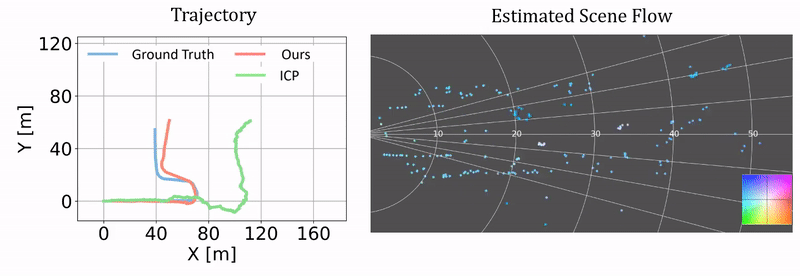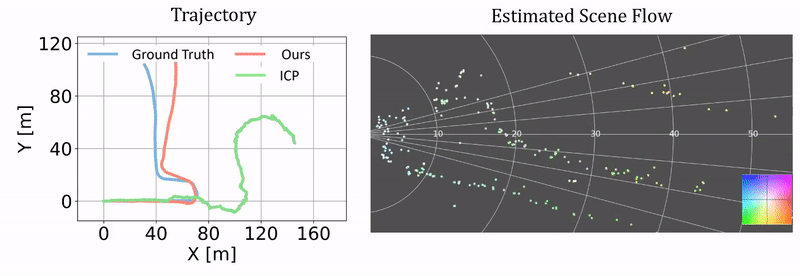
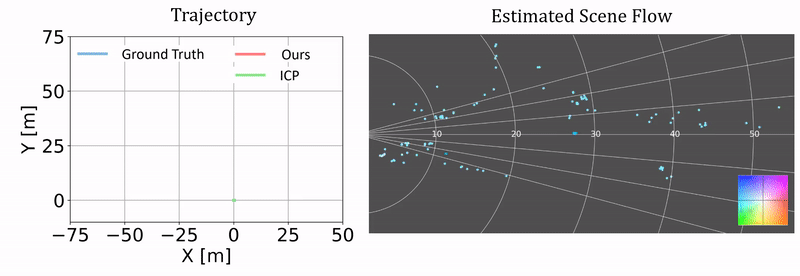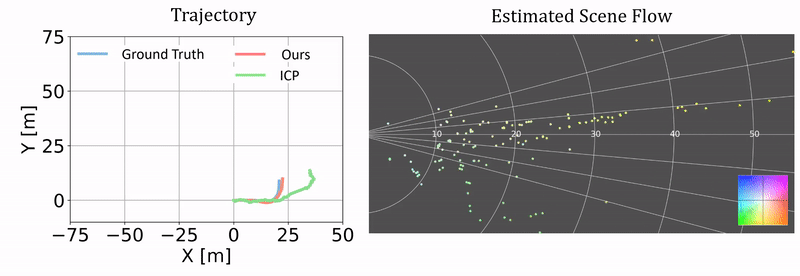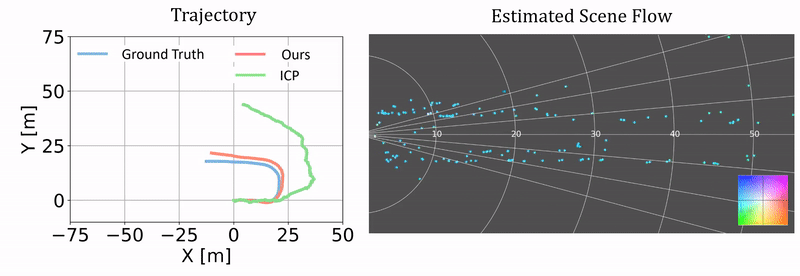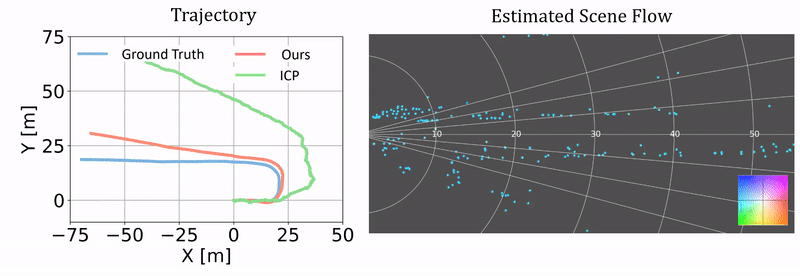
Qualitative results of ego-motion estimation. The left compares our odometry results as a byproduct of our approach and the results from ICP. The ground truth is generated using the RTK-GPS/IMU measurements. The right columns shows the correponding scene flow estimation. We plot the results on two challenging test sequences.
Citation
@InProceedings{Ding_2023_CVPR,
author = {Ding, Fangqiang and Palffy, Andras and Gavrila, Dariu M. and Lu, Chris Xiaoxuan},
title = {Hidden Gems: 4D Radar Scene Flow Learning Using Cross-Modal Supervision},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2023},
pages = {9340-9349}
}
}